
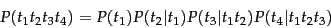
The equation above refers to the chain rule defined by:
Generating a probability distribution is one part of building a usable language processing infrastructure. A useful statistical language model typically depends on the specific need, or problem you want to solve, and of course the domain of your problem. Thus the ability to cluster and partition sequences of words based on their likely occurrence given a query as input can serve as the starting point for connecting probability distributions of linguistic sequences to other semantic information (e.g. equity prices, weather data, abstract concepts). Indeed, I am especially keen to connect linguistic data to other relevant information with useful semantic data to aid in decision-support.
One example would include linking linguistic data to price trends in the equity or commodities markets. Since we know news events can influence price of a given stock (see: News and Stock Prices), we can use a probabilistic language model to both remove unnecessary information from a text corpus and connect retained features to construct a connective semantic representation of the domain.
There are a number of ways one might go about developing language model and semantic representation of the relationships between language and market behavior. First, we might apply a topic modeling approach using Latent Dirichlet Process classify/rank a given document by a set of topics (see the Gensim Module for applying LDA). If for example I was trying to define a set of semantically similar events (communicated in a given text) and connect them with market-sector price trends, one could deploy a neural-net to learn the relationships, and generate new probability distributions based on some user-defined query.
Personally, I think there is more to learn in applying language models and other semantically connected structures to creating meaning from text. In particular, I am interested in exploring the potential of topological data analysis approaches to automating clustering on connectives between linguistic information and semantically related stock price information.
And I will just blurt it out now, I think there is potential value in creating "topological language models" that can be used to automate the formation of linguistic and semantic structures that contain meaning based upon interaction with user queries or targets that require monitoring. Specifically, I think there is opportunity to explore the use of q-analysis and other methods inspired from algebraic topology. But I will discuss this in more detail later.
Comments
Post a Comment